Knowledge→GROWI 移行 (5)
GROWI API の使い方を調べる
GROWI API の使い方を調べます。ドキュメントは下記のページにあります。
私にはドキュメント読んでも具体的なイメージがわかなかったので、やはり Google で検索すると、私にピッタリなサイトが見つかりました。
まずは、そのまま使わせていただきます。requests モジュールが必要なので、.devcontainer/python/requirement.txt に requests を追加してコンテナを再ビルドしました。
そういえば、以前 PostgreSQL にアクセスするのに psycopg2 モジュールを使いました。この時も .devcontainer/python/requirement.txt に psycopg2 を追加してコンテナを再ビルドしました。
簡単に動かしてみます
from crclient import CrClient
crclient = CrClient('growi', 'XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX', 'tiger', './knowledge_to_growi/contents')
crclient.fetch()
確認用に記事を 1 件だけ登録してあるのですが、なんか取得できているようです。
# cd /workspace ; /usr/bin/env /usr/local/bin/python3.8 /root/.vscode-server/extensions/ms-python.python-2021.12.1559732655/pythonFiles/lib/python/debugpy/launcher 43313 -- /workspace/knowledge_to_growi/crclient_sample.py
skip item: {'_id': '61f9120a32a52003888290b5', 'status': 'published', 'grant': 1, 'grantedUsers': [], 'liker': [], 'seenUsers': ['61f7bcc6834bc4803f0e2bfa'], 'commentCount': 0, 'createdAt': '2022-02-01T10:57:14.468Z', 'updatedAt': '2022-02-01T10:57:14.488Z', 'path': '/user/tiger/自分自身のこと', 'creator': '61f7bcc6834bc4803f0e2bfa', 'lastUpdateUser': {'_id': '61f7bcc6834bc4803f0e2bfa', 'isGravatarEnabled': False, 'isEmailPublished': True, 'lang': 'ja_JP', 'status': 2, 'admin': False, 'createdAt': '2022-01-31T10:41:10.624Z', 'username': 'tiger', 'email': 'tiger@example.com', 'lastLoginAt': '2022-02-01T10:49:07.549Z', 'imageUrlCached': '/images/icons/user.svg', 'name': 'tiger62shin'}, 'redirectTo': None, 'grantedGroup': None, '__v': 1, 'revision': '61f9120a32a52003888290b9'}
skip item: {'_id': '61f7bd73834bc4803f0e2c25', 'status': 'published', 'grant': 1, 'grantedUsers': ['61f7bcc6834bc4803f0e2bfa'], 'liker': [], 'seenUsers': ['61f7bcc6834bc4803f0e2bfa'], 'commentCount': 0, 'createdAt': '2022-01-31T10:44:03.214Z', 'updatedAt': '2022-01-31T10:44:03.239Z', 'path': '/user/tiger', 'creator': '61f7bcc6834bc4803f0e2bfa', 'lastUpdateUser': {'_id': '61f7bcc6834bc4803f0e2bfa', 'isGravatarEnabled': False, 'isEmailPublished': True, 'lang': 'ja_JP', 'status': 2, 'admin': False, 'createdAt': '2022-01-31T10:41:10.624Z', 'username': 'tiger', 'email': 'tiger@example.com', 'lastLoginAt': '2022-02-01T10:49:07.549Z', 'imageUrlCached': '/images/icons/user.svg', 'name': 'tiger62shin'}, 'redirectTo': None, 'grantedGroup': None, '__v': 1, 'revision': '61f7bd73834bc4803f0e2c2b'}```
このソースを読んで、動きを確認したことで、なんとなく感覚はつかめたような気がします。API である URL にパラメタを付けて GET / POST でリクエストすると結果が JSON で帰ってくるという一般的な Web API と理解しました。
当初、この CrClient をそのままか、若干の修正で使わせていただこうと思っていたのですが、
- データ移行なので更新の機能は必要ない
- 1 回だけ新規登録できれば良い。失敗したらマニュアルで削除して再実行すれば良い
- 添付ファイルが付けられない
ということで、やはり自分で作ることにしました。
必要な機能は多くはなく
- 記事の新規登録
- 記事へのファイル添付
添付したファイルの url が変わるはずなので、下記のような手順になると思う- 記事を新規登録する
- 記事にファイルを添付する
- 記事の添付ファイル参照 URL を書き換える
以下では機能ごとに調べていきますが、先にこれまで記載したサイトの他に参考にさせて頂いたのですがサイトを載せておきます。
あと、GROWI API のドキュメントのサイトにある OpenAPI specification はよく参照しました。
以下の GROWI の API 利用の例では、今回のデータ移行に必要なパラメータやレスポンスのみ記載しました。
記事の新規登録
| 項目 | 値 |
|---|---|
| URL | _api/v3/pages |
| Method | POST |
| Query Paramaters | access_token : API Token user : ユーザID |
| Payload | body : 本文 path : 記事のパス |
| Response | id : 記事のID path : 記事のパス revision : 記事のリビジョン |
import requests
url = 'http://growi:3000/_api/v3/pages'
params = {"access_token": "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX",
"user": "tiger"}
path = "新規記事登録のサンプル"
content = "この記事は GROWI API を使って登録した記事です。"
payload = {"body": content, "path": "/tiger/{}".format(path)}
res = requests.post(url, data=payload, params=params)
pages_res = res.json()
print('id : ' + pages_res['page']['id'])
print('path : ' + pages_res['page']['path'])
print('revision : ' + pages_res['page']['revision'])
このプログラムを実行するとコンソールに下記のように出力されます。
root@8949de830c08:/workspace# /usr/bin/env /usr/local/bin/python3.8 /root/.vscode-server/extensions/ms-python.python-2021.12.1559732655/pythonFiles/lib/python/debugpy/launcher 39727 -- /workspace/knowledge_to_growi/growiapi_sample1.py id : 61fa6161a03e4c6720a5f36a path : /tiger/新規記事登録のサンプル revision : 61fa6161a03e4c6720a5f36e
ブラウザで確認してみます。

ちゃんと登録されました。
記事へのファイル添付
| 項目 | 値 |
|---|---|
| URL | _api/attachments.add |
| Method | POST |
| Query Paramaters | access_token : API Token user : ユーザID |
| Payload | page_id : 記事のID path : 記事のバス 記事の新規登録で戻ってきた値を指定 |
| file | ファイル名, ファイル本体 |
| Response | id : 添付ファイルのID originalName : ファイル名 filePathProxied : 添付ファイルのパス |
先に作成した記事に下記の画像を添付してみます。

import requests
url = 'http://growi:3000/_api/attachments.add'
params = {"access_token": "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX",
"user": "tiger"}
file = {'file': ('setsubun_mamemaki.png',
open('./knowledge_to_growi/attachments/setsubun_mamemaki.png', 'rb'),
'image/png')}
payload = {'page_id': '61fa6161a03e4c6720a5f36a',
'path': '/tiger/新規記事登録のサンプル'}
res = requests.post(url, data=payload, files=file, params=params)
res.raise_for_status
attachments_res = res.json()
print('id : {} , originalName : {} , filePathProxied : {} '
.format(attachments_res['attachment']['id'],
attachments_res['attachment']['originalName'],
attachments_res['attachment']['filePathProxied']))
このプログラムを実行するとコンソールに下記のように出力されます。
cd /workspace ; /usr/bin/env /usr/local/bin/python3.8 /root/.vscode-server/extensions/ms-python.python-2022.0.1786462952/pythonFiles/lib/python/debugpy/launcher 40267 -- /workspace/knowledge_to_growi/growiapi_sample2.py id : 61fe69c0f6ed08f016d32137 , originalName : setsubun_mamemaki.png , filePathProxied : /attachment/61fe69c0f6ed08f016d32137 root@83fe8d69003a:/workspace#
ブラウザで確認してみます。

ちゃんと添付されました。
記事の更新
| 項目 | 値 |
|---|---|
| URL | _api/pages.update |
| Method | POST |
| Query Paramaters | access_token : API Token user : ユーザID |
| Payload | body : 本文 pageTags : タグのリスト page_id : 記事のID (*) path : 記事のバス (*) revision_id : リビジョンID(*) (*) 記事の新規登録で戻ってきた値を指定 |
| Response | revision : 記事のリビジョン (*) (*)更新するたびにリビジョンが変わるので何度も更新する場合は注意が必要 |
データ移行では本来、記事を更新する必要はないのですが、記事内の添付ファイル参照の url を書き換える必要があります。
下のソースは最初に登録した記事に添付ファイルの画像を表示するように更新するものです。
import requests
url = 'http://growi:3000/_api/pages.update'
params = {"access_token": "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX",
"user": "tiger"}
content = 'この記事は GROWI API を使って登録した記事です。' \
'\n\n' \
''
payload = {'body': content,
'page_id': '61fa6161a03e4c6720a5f36a',
'path': '/tiger/新規記事登録のサンプル',
'revision_id': '61fa6161a03e4c6720a5f36e'}
res = requests.post(url, data=payload, params=params)
res.raise_for_status
ブラウザで確認してみます。

記事が更新され、画像が表示されました。
以上で、データ移行に必要な GROWI API の使い方はわかったのですが、その他にも以下のような API について使い方を調べました。
記事の一覧
| 項目 | 値 |
|---|---|
| URL | _api/pages.list |
| Method | GET |
| Query Paramaters | access_token : API Token user : ユーザID limit : 最大取得件数、-1 を指定すると全件 |
| Payload | N/A |
| Response | _id : 記事のID path : 記事のパス revision : 記事のリビジョン |
今回のデータ移行では、最初に全ての記事のリストを取得しておき、移行対象記事の存在チェックに利用しました。
import requests
url = 'http://growi:3000/_api/pages.list'
params = {"access_token": "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX",
'user': 'tiger',
'limit': -1}
res = requests.get(url, params=params)
res.raise_for_status
pages_list_res = res.json()
for page in pages_list_res['pages']:
print('id : {} / path : {} / revision : {} '
.format(page['_id'], page['path'], page['revision']))
このプログラムを実行するとコンソールに下記のように出力されます。
# /usr/bin/env /usr/local/bin/python3.8 /root/.vscode-server/extensions/ms-python.python-2022.0.1786462952/pythonFiles/lib/python/debugpy/launcher 41573 -- /workspace/knowledge_to_growi/growiapi_sample4.py id : 61fa6161a03e4c6720a5f36a / path : /tiger/新規記事登録のサンプル / revision : 61fa7643a03e4c6720a5f4f2 id : 61f9120a32a52003888290b5 / path : /user/tiger/自分自身のこと / revision : 61f9120a32a52003888290b9 id : 61f7bd73834bc4803f0e2c25 / path : /user/tiger / revision : 61f7bd73834bc4803f0e2c2b
添付ファイルの一覧
| 項目 | 値 |
|---|---|
| URL | _api/v3/attachment/list |
| Method | GET |
| Query Paramaters | access_token : API Token user : ユーザID pageid : 記事の ID (*) page : 添付ファイル一覧のページ番号 (*) 記事の新規登録 / 記事の一覧の取得で戻ってきた値を指定 |
| Payload | N/A |
| Response | id : 添付ファイルのID originalName : 添付ファイル名 filePathProxied : 添付ファイルの url パス |
この API は少し注意が必要です。取得できる添付ファイル情報は画面に表示される添付ファイル一覧の 1 ページ分しか取得できません。幸い page パラメーターで取得する一覧のページ番号を指定できますので、データが取得できなくなるまでページ番号をインクリメントしながら取得します。
今回のデータ移行では、すでに存在している記事に対して移行する際の添付ファイルの存在チェックに利用しました。
import requests
url = 'http://growi:3000/_api/v3/attachment/list'
params = {"access_token": "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX",
'user': 'tiger',
'pageId': '61fa6161a03e4c6720a5f36a',
'page': 1}
res = requests.get(url, params=params)
res.raise_for_status
attachment_list_res = res.json()
for attachment in attachment_list_res['paginateResult']['docs']:
print('id : {} , originalName : {} , filePathProxied : {} '
.format(attachment['id'], attachment['originalName'],
attachment['filePathProxied']))
このプログラムを実行するとコンソールに下記のように出力されます。
# cd /workspace ; /usr/bin/env /usr/local/bin/python3.8 /root/.vscode-server/extensions/ms-python.python-2022.0.1786462952/pythonFiles/lib/python/debugpy/launcher 41445 -- /workspace/knowledge_to_growi/growiapi_sample5.py id : 61fa6799a03e4c6720a5f490 , originalName : setsubun_mamemaki.png , filePathProxied : /attachment/61fa6799a03e4c6720a5f490
添付ファイルの削除
| 項目 | 値 |
|---|---|
| URL | _api/attachments.remove |
| Method | POST |
| Query Paramaters | access_token : API Token user : ユーザID |
| Payload | attachment_id : 添付ファイルID 記事へのファイル添付 / 添付ファイルの一覧取得で戻ってきた値を指定 |
| Response | - |
今回のデータ移行では、すでに存在している添付ファイルを置き換える際の削除に利用しました。
import requests
url = 'http://growi:3000/_api/attachments.remove'
params = {"access_token": "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX",
'user': 'tiger'}
payload = {'attachment_id': '61fa6799a03e4c6720a5f490'}
res = requests.post(url, data=payload, params=params)
res.raise_for_status
このサンプルでは「記事へのファイル添付」で添付したファイルを削除しています。

添付ファイルが削除されたので表示されなくなりました。
以上です。
あと、既存の記事の取得とかあればよかったのでしょうが、今回のデータ移行には必要なかったので調べませんでした。
Knowledge→GROWI 移行 (4)
Visual Studio Code に GROWI の Docker コンテナを追加
GROWI は元々が Docker コンテナで導入するのが基本のようなので、それを利用します。
テスト用だし git clone する必要はないので、ここ から growi-docker-compose を zip ファイルでダウンロードします。
ダウンロードしたファイルを作業ディレクトリに解凍します。
% unzip growi-docker-compose-master.zip % ls -l growi-docker-compose-master total 64 -rw-r--r--@ 1 tiger staff 412 12 30 23:02 Dockerfile -rw-r--r--@ 1 tiger staff 980 12 30 23:02 Dockerfile.v42x -rw-r--r--@ 1 tiger staff 1069 12 30 23:02 LICENSE -rw-r--r--@ 1 tiger staff 3612 12 30 23:02 README.md -rw-r--r--@ 1 tiger staff 1266 12 30 23:02 docker-compose.dev.yml -rw-r--r--@ 1 tiger staff 2217 12 30 23:02 docker-compose.v42x.yml -rw-r--r--@ 1 tiger staff 2305 12 30 23:02 docker-compose.v43x-v446.yml -rw-r--r--@ 1 tiger staff 2429 12 30 23:02 docker-compose.yml drwxr-xr-x@ 4 tiger staff 128 12 30 23:02 elasticsearch drwxr-xr-x@ 7 tiger staff 224 12 30 23:02 examples drwxr-xr-x@ 5 tiger staff 160 12 30 23:02 hackmd
かるく(?) docker-compose.yml を覗いてみます。growi 本体と mongodb, elasticsearch の 3 つのコンテナで構成されているようです。
.devcontainer フォルダの直下に GROWI 用の Dockerfile を置くフォルダ growi を作成して growi-docker-compose-master/Dockerfile, LICENSE, README.md をコビーします (LICENSE, README.md は動作には必要ないですが)。
以下の例はカレントディレクトがプロジェクトフォルダでプロジェクトフォルダ直下に growi-docker-compose-master.zip を展開しています。
% mkdir -p .devcontainer/growi % cp growi-docker-compose-master/Dockerfile .devcontainer/growi % cp growi-docker-compose-master/LICENSE .devcontainer/growi % cp growi-docker-compose-master/README.md .devcontainer/growi
次に growi-docker-compose-master/elasticsearch をフォルダごと .devcontainer にコピーします。
% cp -R growi-docker-compose-master/elasticsearch .devcontainer
.devcontainer/docker-compose.yml に GROWI の設定を記述するのですが、基本的には growi-docker-compose-master/docker-compose.yml の内容を追記すれば良いはずです。
version: '3'
services:
python38:
restart: always
build: python
container_name: 'python38'
working_dir: '/workspace'
tty: true
extra_hosts:
- "fluorine.kt.asasystems.co.jp:192.168.100.78"
environment:
- DISPLAY=${IP_ADDR}:0.0
volumes:
- ..:/workspace:cached
- /tmp/.X11-unix:/tmp/.X11-unix
postgres:
restart: always
build: postgres
container_name: 'postgres12'
ports:
- 5433:5433
environment:
POSTGRES_USER: postgres
POSTGRES_PASSWORD: postgres
volumes:
- ./postgres/initdb:/docker-entrypoint-initdb.d
growi:
build: growi
container_name: 'growi'
ports:
- 127.0.0.1:3000:3000 # localhost only by default
links:
- mongo:mongo
- elasticsearch:elasticsearch
depends_on:
- mongo
- elasticsearch
environment:
- MONGO_URI=mongodb://mongo:27017/growi
- ELASTICSEARCH_URI=http://elasticsearch:9200/growi
- PASSWORD_SEED=changeme
- FILE_UPLOAD=mongodb # activate this line if you use MongoDB GridFS rather than AWS
# - FILE_UPLOAD=local # activate this line if you use local storage of server rather than AWS
# - MATHJAX=1 # activate this line if you want to use MathJax
# - PLANTUML_URI=http:// # activate this line and specify if you use your own PlantUML server rather than public plantuml.com
# - HACKMD_URI=http:// # activate this line and specify HackMD server URI which can be accessed from GROWI client browsers
# - HACKMD_URI_FOR_SERVER=http://hackmd:3000 # activate this line and specify HackMD server URI which can be accessed from this server container
# - FORCE_WIKI_MODE='public' # activate this line to force wiki public mode
# - FORCE_WIKI_MODE='private' # activate this line to force wiki private mode
entrypoint: "dockerize
-wait tcp://mongo:27017
-wait tcp://elasticsearch:9200
-timeout 60s
/docker-entrypoint.sh"
command: ["yarn migrate && node -r dotenv-flow/config --expose_gc dist/server/app.js"]
restart: unless-stopped
volumes:
- growi_data:/data
mongo:
image: mongo:4.4
container_name: 'mongo'
restart: unless-stopped
volumes:
- mongo_configdb:/data/configdb
- mongo_db:/data/db
elasticsearch:
build: elasticsearch
container_name: 'elasticsearch'
environment:
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms256m -Xmx256m" # increase amount if you have enough memory
- LOG4J_FORMAT_MSG_NO_LOOKUPS=true # CVE-2021-44228 mitigation for Elasticsearch <= 6.8.20/7.16.0
ulimits:
memlock:
soft: -1
hard: -1
restart: unless-stopped
volumes:
- es_data:/usr/share/elasticsearch/data
- ./elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
volumes:
growi_data:
driver_opts:
type: none
device: /Users/user/workspace/project/ToolsByPython/docker_volumes/growi_data
o: bind
mongo_configdb:
driver_opts:
type: none
device: /Users/user/workspace/project/ToolsByPython/docker_volumes/mongo_configdb
o: bind
mongo_db:
driver_opts:
type: none
device: /Users/user/workspace/project/ToolsByPython/docker_volumes/mongo_db
o: bind
es_data:
driver_opts:
type: none
device: /Users/user/workspace/project/ToolsByPython/docker_volumes/es_data
o: bind
es_plugins:
driver_opts:
type: none
device: /Users/user/workspace/project/ToolsByPython/docker_volumes/es_plugins
o: bind
変更点は以下の通りです。
- growi コンテナ
- mongo コンテナと elasticsearch コンテナは変更なし
- volumes
デフォルトのままでもよかったが、なんとなくローカルのディレクトリを指定した。
最初、.devcontainer ディレクトリ下のディレクトリを指定したところ、パスに隠しディレトリがあるとコンテナのビルドでエラーになってしまいました。パスに隠しディレクトリを含まない場所にディレクトリを作成して指定しました。
設定は以上で終了です。Visual Studio Code を起動します。Docker コンテナが正常に起動されたならブラウザから http://localhost:3000 にアクセスして GROWI が正しく起動されていることを確認します。

上の画面から管理者ユーザを登録して GROWI の初期設定を行います。データ移行のテスト用なので、最低限の設定しか行いませんでした。

上の図のように「サイトURL」のみ設定しました。
次に実際に記事の移行先となる一般ユーザを登録して、プログラムから GROWI API を利用するための API Token を取得します。
- 管理者により「ユーザー管理」から一般ユーザの仮パスワードを発行
- 一般ユーザのメールアドレスと仮パスワードでログイン
- ユーザ情報の入力
API Token を発行
ページ右上に表示されているユーザ ID をクリックして [設定] ボタンをクリックします。
これで、Knowledge→GROWI データ移行のためのテスト環境が整いました。長かった。
毎度のことですが、プログラミングって環境作るのが大変で、経験したことない人は環境作るところで挫折するっていう話をどこかで聞いた (読んだ) ことがありますが、本当な気がします。
Knowledge→GROWI 移行 (3)
Python で Knowledge のデータベース (PostgreSQL) にアクセスしてみる
Python で PostgreSQL にアクセスするする方法はさっぱり分かりませんから、いつものように Google で検索します。
たくさんヒットしますが、下記のサイトを参考にさせていただきました。
まずは、knowledges テーブルから knowledge_id と title を取り出してみます。全部取り出すと大変なので、条件をつけて 5 件だけ取り出します。
import psycopg2
from psycopg2.extras import DictCursor
# DB接続情報
DB_HOST = 'postgres'
DB_PORT = '5432'
DB_NAME = 'knowledgedb'
DB_USER = 'kbadmin'
DB_PASS = '**********'
# DB接続関数
def get_connection():
return psycopg2.connect('postgresql://{user}:{password}@{host}:{port}/{dbname}'
.format(user=DB_USER, password=DB_PASS, host=DB_HOST, port=DB_PORT, dbname=DB_NAME))
with get_connection() as conn:
with conn.cursor(cursor_factory=DictCursor) as cur:
cur.execute('select knowledge_id, title from knowledges '
'where knowledge_id in (217, 227, 229, 236, 240)')
for row in cur:
print(str(row['knowledge_id']) + ' : ' + row['title'])
参考にさせてもらったサイトのサンプルを幾つか組み合わせただけです。取得した結果から列のデータを辞書式で取得したかったので、DictCursor を使いました。
結果はこんな感じです。
root@ced5581a8a4a:/workspace# cd /workspace ; /usr/bin/env /usr/local/bin/python3.8 /root/.vscode-server/extensions/ms-python.python-2021.12.1559732655/pythonFiles/lib/python/debugpy/launcher 41367 -- /workspace/knowledge_to_growi/postgres_sample.py 240 : Mac 関連のメモ 229 : Visual Studio Code 設定 227 : Docker 236 : POP3 サーバ内メールを取得して IMAP メールボックスに配信 217 : ORACLE メモ
続けて、添付ファイルを取得してみます。
cur.execute('select file_no, knowledge_id, comment_no, draft_id, file_name, file_binary '
'from knowledge_files where file_no = 556')
for row in cur:
print(row['file_name'])
file_name = './knowledge_to_growi/attachments/' \
+ row['file_name']
with open(file_name, 'wb') as f:
f.write(row['file_binary'])
 添付ファイルもちゃんと取得できました。ところが、このままではちょっと問題があります。
添付ファイルもちゃんと取得できました。ところが、このままではちょっと問題があります。
私が実現したいのは「見出しや本文を取り出しつつ、その添付ファイルも取り出す」ことなので、上のコーディングだと cursor が 1 つしかないので knowledges から「見出し」や「本文」を一旦全部取り出してから、knowledge_files から添付ファイルを取り出すようにしないと上手くいかないと思います。それでもいいのですが、あまり好きな方法ではないので knowledges 用と knowledge_files 用の 2 つのカーソルを使います。ついでに目的の記事に添付されているファイルのみを取り出すようにします。
with conn.cursor(cursor_factory=DictCursor) as knowledges_cur:
knowledges_cur.execute('select knowledge_id, title from knowledges '
'where knowledge_id in (217, 227, 229, 236, 240)')
for knowledge_row in knowledges_cur:
print(str(knowledge_row['knowledge_id']) + ' : ' + knowledge_row['title'])
with conn.cursor(cursor_factory=DictCursor) as file_cur:
file_cur.execute('select file_no, knowledge_id, comment_no, draft_id, file_name, file_binary '
'from knowledge_files '
'where knowledge_id = %s', (knowledge_row['knowledge_id'], ))
for file_row in file_cur:
print(file_row['file_name'])
file_name = './knowledge_to_growi/attachments/' + file_row['file_name']
with open(file_name, 'wb') as f:
f.write(file_row['file_binary'])
だいぶ、ネストが深くなりましたが、これで knowledges テーブルから記事を取り出しつつ、knowledge_files テーブルからその記事の添付ファイルを取り出すことが出来ました。
draft_knowledges からも同様の方法で取得できるはずです。
これで、GROWI に移行するデータを取得する目処がたちました。
Knowledge→GROWI 移行 (2)
Visual Studio Code に PostgreSQL の Docker コンテナを追加
コーディングまでの道のりは長い。
上の記事で Visual Studio Code で Python の実行環境である Docker コンテナに接続して Python のプログラムが実行できるところまでは設定しましたが、Knowledge から移行データを抜くためのデータベース環境を作っていませんでした。
今回は Visual Studio Code に PostgreSQL の Docker コンテナを追加します。
まずは、Google で PostgreSQL の Dockerfile の雛形を探します。ありがたいことに手順が解説されているサイトがたくさん見つかります。私は下記のサイトを参考にさせていただきました。
まず、.devcontainer フォルダの直下に PostgreSQL 用の Dockerfile 等を置くフォルダを作成します。
.devcontainer/postgres
このフォルダに上のサイトを参考にして Dockerfile を作成します。
FROM postgres:12-alpine ENV LANG ja_JP.UTF-8 ENV LANGUAGE ja_JP:ja ENV LC_ALL ja_JP.UTF-8 ENV TZ JST-9
ENV は LANG だけあれば良いようですが、他のコンテナでも設定しているので、LANGUAGE, LC_ALL, TZ も設定しておきました。特に意味はないです。
このままでも PostgreSQL のコンテナは問題なく起動しますが、目的のデータベースも何もない状態なのでコンテナのビルド時に移行対象のデータベースをインポートしたい思います。ここでも Google 先生に頼ります。下記のようなサイトが見つかりました。
/docker-entrypoint-initdb.d に置かれた .sql / .sh ファイルが 1 度だけ実行されるそうです。では、/docker-entrypoint-initdb.d に置くファイルを準備します。
まず、移行元サーバーから移行元データベースのダンプを取得してきます。
$ pg_dump knowledgedb -U kbadmin >knowledgedb.dump
次にデータベース / ユーザを作成する SQL ファイルを準備します。ファイル名は createdb.sql とします。
CREATE ROLE kbadmin LOGIN PASSWORD '**********'; ALTER ROLE kbadmin SUPERUSER; create database knowledgedb;
最後にデータベース / ユーザを作成してデータをインポートするシェル (01-initdb.sh) を作成します。
#!/bin/sh PGPASSWORD=********** psql < /docker-entrypoint-initdb.d/sql/createdb.sql psql -U kbadmin -d knowledgedb < /docker-entrypoint-initdb.d/sql/knowledgedb.dump
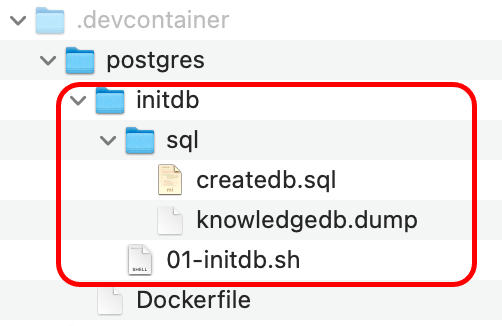
これらのファイルを下図のように .devcontainer/postgres フォルダに配置します。
docker-compose.yml に PostgreSQL の設定を追加します。
version: '3'
services:
python38:
restart: always
build: python
container_name: 'python38'
working_dir: '/workspace'
tty: true
extra_hosts:
- "fluorine.kt.asasystems.co.jp:192.168.100.78"
environment:
- DISPLAY=${IP_ADDR}:0.0
volumes:
- ..:/workspace:cached
- /tmp/.X11-unix:/tmp/.X11-unix
postgres:
restart: always
build: postgres
container_name: 'postgres12'
ports:
- 5433:5433
environment:
POSTGRES_USER: postgres
POSTGRES_PASSWORD: **********
volumes:
- ./postgres/initdb:/docker-entrypoint-initdb.d
postgres の公式 docker image は envrionement の値を読みとり初期設定を行なう機能があるそうです。私は POSTGRES_USER と POSTGRES_PASSWORD を指定しました。POSTGRES_DB を省略すると POSTGRES_USER で指定した名前と同じ名前のデータベースが作成されるそうです。
あと、volumes でデータベースを初期化するシェルのあるフォルダを /docker-entrypoint-initdb.d に割り当てます。
これで、Docker コンテナの設定は完了しました。
Visual Studio Code を起動してみます。エラーなく起動できたら Python と PostgreSQL の Docker コンテナが起動しているか確認してみます。
% docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 02ee35af85df toolsbypython_devcontainer_postgres "docker-entrypoint.s…" 22 hours ago Up 6 minutes 5432/tcp, 0.0.0.0:5433->5433/tcp postgres12 ced5581a8a4a toolsbypython_devcontainer_python38 "python3" 22 hours ago Up 6 minutes 6006/tcp python38
問題なさそうです。では、Knowledge のデータベースが作成されているかどうかを確認してみます。
まず、PostgreSQL の Docker コンテナにログインします。私は Docker コンテナにログインするのに下記のようなシェルを作成しています。
docker-shell.sh
#!/bin/sh
docker exec -i -t `docker ps | grep "$1" | awk '{print $1;}'` /bin/bash
では、ログイン
% docker-shell.sh postgres bash-5.1#
データベースが作成 (インポート) されているか確認するために psql を起動してテーブルの一覧でも表示してみます。
bash-5.1# psql -U kbadmin -d knowledgedb
psql (12.9)
Type "help" for help.
knowledgedb=# \d
List of relations
Schema | Name | Type | Owner
--------+-------------------------------+----------+---------
public | access_logs | table | kbadmin
public | access_logs_no_seq | sequence | kbadmin
public | account_images | table | kbadmin
public | account_images_image_id_seq | sequence | kbadmin
public | activities | table | kbadmin
public | activities_activity_no_seq | sequence | kbadmin
public | badges | table | kbadmin
public | badges_no_seq | sequence | kbadmin
public | comments | table | kbadmin
public | comments_comment_no_seq | sequence | kbadmin
public | confirm_mail_changes | table | kbadmin
public | draft_item_values | table | kbadmin
public | draft_knowledges | table | kbadmin
public | draft_knowledges_draft_id_seq | sequence | kbadmin
public | events | table | kbadmin
public | functions | table | kbadmin
public | groups | table | kbadmin
public | groups_group_id_seq | sequence | kbadmin
public | hash_configs | table | kbadmin
public | item_choices | table | kbadmin
public | knowledge_edit_groups | table | kbadmin
public | knowledge_edit_users | table | kbadmin
public | knowledge_files | table | kbadmin
public | knowledge_files_file_no_seq | sequence | kbadmin
public | knowledge_groups | table | kbadmin
public | knowledge_histories | table | kbadmin
public | knowledge_item_values | table | kbadmin
public | knowledge_tags | table | kbadmin
public | knowledge_users | table | kbadmin
public | knowledges | table | kbadmin
public | knowledges_knowledge_id_seq | sequence | kbadmin
public | ldap_configs | table | kbadmin
public | like_comments | table | kbadmin
public | like_comments_no_seq | sequence | kbadmin
public | likes | table | kbadmin
public | likes_no_seq | sequence | kbadmin
public | locales | table | kbadmin
public | login_histories | table | kbadmin
public | mail_configs | table | kbadmin
public | mail_hook_conditions | table | kbadmin
public | mail_hook_ignore_conditions | table | kbadmin
public | mail_hooks | table | kbadmin
public | mail_hooks_hook_id_seq | sequence | kbadmin
public | mail_locale_templates | table | kbadmin
--More--
なんか大丈夫そうです。2, 3のテーブルについて select してみましたが中身が入っているので問題ないでしょう。
Knowledge→GROWI 移行 (1)
移行元データを探る
さて、
にも書きましたが、個人で利用している情報共有サービスを Knowledge - Free knowledge base system から OSS開発wikiツールのGROWI に移行する話を進めていきます。
まずは、Knowledge のデータベースから移行元のデータ (本文と添付ファイル) を探っていきます。
Knowledge のデータベースは PostgreSQL なのでクライアントアプリケーションである psql を使って接続します。
$ psql -U postgres -d knowledge psql (11.14 (Debian 11.14-0+deb10u1)) "help" でヘルプを表示します。 knowledge=>
テーブルの一覧を確認してみます
knowledge=> \dt;
リレーション一覧
スキーマ | 名前 | 型 | 所有者
----------+-----------------------------+----------+---------
public | access_logs | テーブル | kbadmin
public | account_images | テーブル | kbadmin
public | activities | テーブル | kbadmin
public | badges | テーブル | kbadmin
public | comments | テーブル | kbadmin
public | confirm_mail_changes | テーブル | kbadmin
public | draft_item_values | テーブル | kbadmin
public | draft_knowledges | テーブル | kbadmin
public | events | テーブル | kbadmin
public | functions | テーブル | kbadmin
public | groups | テーブル | kbadmin
public | hash_configs | テーブル | kbadmin
public | item_choices | テーブル | kbadmin
public | knowledge_edit_groups | テーブル | kbadmin
public | knowledge_edit_users | テーブル | kbadmin
public | knowledge_files | テーブル | kbadmin
public | knowledge_groups | テーブル | kbadmin
public | knowledge_histories | テーブル | kbadmin
public | knowledge_item_values | テーブル | kbadmin
public | knowledge_tags | テーブル | kbadmin
public | knowledge_users | テーブル | kbadmin
public | knowledges | テーブル | kbadmin
public | ldap_configs | テーブル | kbadmin
public | like_comments | テーブル | kbadmin
public | likes | テーブル | kbadmin
public | locales | テーブル | kbadmin
public | login_histories | テーブル | kbadmin
public | mail_configs | テーブル | kbadmin
public | mail_hook_conditions | テーブル | kbadmin
public | mail_hook_ignore_conditions | テーブル | kbadmin
public | mail_hooks | テーブル | kbadmin
public | mail_locale_templates | テーブル | kbadmin
public | mail_posts | テーブル | kbadmin
public | mail_properties | テーブル | kbadmin
public | mail_templates | テーブル | kbadmin
public | mails | テーブル | kbadmin
public | notices | テーブル | kbadmin
public | notification_status | テーブル | kbadmin
public | notifications | テーブル | kbadmin
public | notify_configs | テーブル | kbadmin
public | notify_queues | テーブル | kbadmin
public | participants | テーブル | kbadmin
public | password_resets | テーブル | kbadmin
public | pins | テーブル | kbadmin
public | point_knowledge_histories | テーブル | kbadmin
public | point_user_histories | テーブル | kbadmin
public | provisional_registrations | テーブル | kbadmin
public | proxy_configs | テーブル | kbadmin
public | read_marks | テーブル | kbadmin
public | role_functions | テーブル | kbadmin
public | roles | テーブル | kbadmin
public | service_configs | テーブル | kbadmin
public | service_locale_configs | テーブル | kbadmin
public | stock_knowledges | テーブル | kbadmin
public | stocks | テーブル | kbadmin
public | survey_answers | テーブル | kbadmin
public | survey_choices | テーブル | kbadmin
public | survey_item_answers | テーブル | kbadmin
public | survey_items | テーブル | kbadmin
public | surveys | テーブル | kbadmin
public | system_attributes | テーブル | kbadmin
public | system_configs | テーブル | kbadmin
public | systems | テーブル | kbadmin
public | tags | テーブル | kbadmin
public | template_items | テーブル | kbadmin
public | template_masters | テーブル | kbadmin
public | tokens | テーブル | kbadmin
public | user_alias | テーブル | kbadmin
public | user_badges | テーブル | kbadmin
public | user_configs | テーブル | kbadmin
public | user_groups | テーブル | kbadmin
public | user_notifications | テーブル | kbadmin
public | user_roles | テーブル | kbadmin
public | users | テーブル | kbadmin
public | view_histories | テーブル | kbadmin
public | votes | テーブル | kbadmin
public | webhook_configs | テーブル | kbadmin
public | webhooks | テーブル | kbadmin
(78 行)
knowledge=>
たくさんありますね。この中から名前から想像してめぼしいものをピックアップします。
- knowledge_files
- knowledges
- draft_knowledges
一つ一つ、確認していきます。knowledge_files はたぶん添付ファイルだと思うので、後回しにします。
knowledges のカラムを確認
knowledge=> \d knowledges;
テーブル "public.knowledges"
列 | 型 | 照合順序 | Null 値を許容 | デフォルト
-----------------+-----------------------------+----------+---------------+--------------------------------------------------
knowledge_id | bigint | | not null | nextval('knowledges_knowledge_id_seq'::regclass)
title | character varying(1024) | | not null |
content | text | | |
public_flag | integer | | |
tag_ids | character varying(1024) | | |
tag_names | text | | |
like_count | bigint | | |
comment_count | integer | | |
view_count | bigint | | |
type_id | integer | | |
notify_status | integer | | |
point | integer | | not null | 0
anonymous | integer | | |
insert_user | integer | | |
insert_datetime | timestamp without time zone | | |
update_user | integer | | |
update_datetime | timestamp without time zone | | |
delete_flag | integer | | |
インデックス:
"knowledges_pkc" PRIMARY KEY, btree (knowledge_id)
knowledge=>
knowledge_id, title, content, tag_names あたりが怪しそうなので、下の画像の記事を確認してみます

knowledge=> select knowledge_id, title, content, tag_names from knowledges where knowledge_id = 235;

移行に必要なデータ「見出し」、「本文」、「タグ」はここから取り出せそうです。
実はこのことは後から気付いたのですが、delete_flag をたてて論理削除されているデータがあるようです。まず、delete_flag がどのような値を取るかを確認します。
knowledge=> select delete_flag, count(*) from knowledges group by delete_flag;
delete_flag | count
-------------+-------
0 | 234
1 | 5
(2 行)
予想通り '1' で削除されているようです。なので、移行に必要なデータを取り出す SQL は
select knowledge_id, title, content, tag_names from knowledges where delete_flag = 0;
のようになりそうです。
draft_knowledges は下書きと思います。同じようにして確認していきます。
knowledge=> \d draft_knowledges;
テーブル "public.draft_knowledges"
列 | 型 | 照合順序 | Null 値を許容 | デフォルト
-----------------+-----------------------------+----------+---------------+----------------------------------------------------
draft_id | bigint | | not null | nextval('draft_knowledges_draft_id_seq'::regclass)
knowledge_id | bigint | | |
title | character varying(1024) | | not null |
content | text | | |
public_flag | integer | | |
accesses | text | | |
editors | text | | |
tag_names | text | | |
type_id | integer | | |
insert_user | integer | | |
insert_datetime | timestamp without time zone | | |
update_user | integer | | |
update_datetime | timestamp without time zone | | |
delete_flag | integer | | |
インデックス:
"draft_knowledges_pkc" PRIMARY KEY, btree (draft_id)
knowledge=>
knowledges と同じように draft_id, title, content, tag_names があるのでここから取り出せそうです。下書きの ID は別になっていることに加え knowledge_id というカラムがあります。内容を確認してみます。
knowledge=> select knowledge_id from draft_knowledges;
knowledge_id
--------------
0
0
0
0
0
0
0
0
0
0
0
230
(16 行)
たいていは 0 か null みたいですが、1 つだけ値が入ってます。draft_knowledges.knowledge_id の値で knowledges の方を確認してみます。
knowledge=> select knowledge_id, title, content, tag_names from knowledges where knowledge_id = 230;
つまり、「公開されている記事の下書き」の公開されている記事の ID が入っているようです。1 つしかないし、内容も忘れているのでこの下書きの記事は移行しないことにしました
このような SQL で下書きのデータは取り出せそうです。knowledges と同様に論理削除されているデータは除外しています。
knowledge=> select draft_id, title, content, tag_names from draft_knowledges where (knowledge_id is null or knowledge_id not in (select knowledge_id from knowledges)) and delete_flag = 0;
次は添付ファイルです
同様にカラムを確認します
knowledge=> \d knowledge_files;
テーブル "public.knowledge_files"
列 | 型 | 照合順序 | Null 値を許容 | デフォルト
-----------------+-----------------------------+----------+---------------+--------------------------------------------------
file_no | bigint | | not null | nextval('knowledge_files_file_no_seq'::regclass)
knowledge_id | bigint | | |
comment_no | bigint | | |
draft_id | bigint | | |
file_name | character varying(256) | | |
file_size | double precision | | |
file_binary | bytea | | |
parse_status | integer | | not null |
insert_user | integer | | |
insert_datetime | timestamp without time zone | | |
update_user | integer | | |
update_datetime | timestamp without time zone | | |
delete_flag | integer | | |
インデックス:
"knowledge_files_pkc" PRIMARY KEY, btree (file_no)
"idx_knowledge_files_knowledge_id" btree (knowledge_id)
knowledge=>
knowledge_id または draft_id 毎に file_no で識別されるファイルが格納されているようです。file_name にファイル名、file_size にファイルのサイズ、file_binary にファイル本体があるようです。
試しに SQL だけでファイルを取りだしてみようとして、Google で検索した結果、下記のサイトを見つけました
COPY コマンドでバイナリデータをファイルに出力することはできるが、ファイルの先頭に 25 byte 分のヘッダがついているようです。
copy (select file_binary from knowledge_files where file_name = 'clip-20210606104110.png') to '/var/lib/postgresql/clip-20210606104110.png' (format binary);
Mac で使用できるバイナリエディタを持っていなかったので Windows の Stirling というバイナリエディタを使ってファイルの先頭 25 byte を削ってみました。

Postfix をインストールしたときのスクリーンショットのようです。
これで添付ファイルも取り出せることがわかりました。
本文と添付ファイルとの関係も確認しておこうと思います。上の添付ファイルは下図の記事の赤枠で囲った部分の添付ファイルと思います

knowledge=> select file_no, knowledge_id, file_name from knowledge_files where file_name = 'clip-20210606104110.png';
file_no | knowledge_id | file_name
---------+--------------+-------------------------
556 | 236 | clip-20210606104110.png
(1 行)
knowledge=>
#236 の記事に添付されている 556 番のファイルということで間違いなさそうです。実際の記事はこんな感じです。

開発環境
私が仕事を始めた頃のプログラマーは「紙と鉛筆」があれば仕事ができる時代でしたが (コーディングもコーディングシートに手書きしていた)、今時「紙と鉛筆」でのプログラミングなんてありえないのでパソコンや開発ツール等の道具が必要です。知識だけなら本を読むだけでもなんとかなるとは思いますが、身につかないと思いますし、やはり作ったものは動かしてみたいと思うのが人情でしょう
で、私の開発環境です。
パソコン
MacBook Pro を使っています。 2 年ほど前に整備済品を購入しました。Intel Mac です。整備済品なので特にカスタマイズもしてませんがメモリだけは沢山積んである (32GB) のを選んで購入しました。
ディスプレイは 13 インチで老眼が進んだ身としては少々つらいのですが、フットプリントが小さいほうがよかったのと、ディスプレイは外部ディスプレイをつなげればよいと思ったので 13 インチにしました。
仕事では、Let's Note だったり、ThinkPad だったりするので操作方法の違いになれないこともありますが、仕事と趣味で異なる種類のパソコンを使うことによる気持ちと頭の切り替えでできてよいような気がします。
開発環境とは無関係なのですが、実は整備済品とはいえ新品の Mac を買うのはこれが 4 台目です。最初に買ったのは 30 年位前に買った Macintosh LC です。
私が初めて買ったパソコンです。その後、Macintosh LC630 に買い換えました。
LC は人に譲ってしまいましたが、LC630 はまだ持ってます。インターネットに初めて接続したのも LC630 からでした。
LC630 以降は Dynabook や ThinkPad だったり、自作デスクトップだったりで、MacBook Pro を買うまでは Windows PC がメインでした。
私自身が使った Mac はこんな感じですが、息子用に iMac DV を買っています。
この iMac DV は、ロジックボードだけ形を変えてまだ持っています。iMac DV のロジックボードを PC/AT 用の電源で動かすようにして、確か、Maintosh IIcx の筐体に入れる改造記事に触発されて真似して作ったものです。私は IIci の筐体に入れました。
ブックマークに登録しておいた改造記事のサイトにアクセスしてみましたが、もうどこも残ってないようです。が、Internet Archive に少し残ってました。
このサイトでは iMac を Sun SPARC station IPX の筐体に入れています。
IDE
Visual Studio Code です。これ以上の説明はいらないと思いますが、以下の機能拡張を導入しています。
- Japanese Language Pack for VS Code
- Python extension for Visual Studio Code
- Visual Studio Code Remote - Containers
- Visual Studio Code Remote - SSH
- Visual Studio Code Remote - SSH: Editing Configuration Files
- Visual Studio Code Remote - WSL
- Visual Studio Code Remote Development Extension Pack
- Jupyter Keymaps Extension for Visual Studio Code
- Jupyter Extension for Visual Studio Code
- Renderers for Jupyter Notebooks in Visual Studio Code
- Pylance
- vscode-icons
- File-specific icons in VSCode for improved visual grepping
正直、なんで入っているのかわからないものもあるのですが、とりあえず現在入っているのが上記のものです。
Remote - XXX が入っているのは Remote Development Extension Pack でまとめて導入されたものです。目的は Docker コンテナを使いたかったので、Remote - Containers が入っていればよかったはずです。
ファイルアイコンとかも綺麗に表示されていた方が嬉しいのでいくつか入れました。
Visual Studio Code の設定は未だ試行錯誤中ですが、主な設定を記載します。
まずは色関係
"workbench.colorCustomizations": {
"editor.background": "#1E1E1E",
"editor.lineHighlightBorder": "#1E1E1E",
"editorLineNumber.activeForeground": "#ffffff",
},
背景色を黒にしているのとカレント行の行番号の色を白にしています。工夫したのは、editor.lineHighlightBorder を背景色と同じ色に設定してカレント行の枠線が表示されないようにしたところです。
Python 固有に下記のようなものを設定しています。
"[python]": {
"editor.fontFamily": "SourceHanCodeJP-Regular",
"editor.fontSize": 12,
"editor.insertSpaces": true,
"editor.tabSize": 4,
"editor.rulers": [128],
"editor.renderIndentGuides": false,
"files.insertFinalNewline": true,
"files.trimTrailingWhitespace": true,
},
Python 固有にしたのは他の言語もやってみたいので設定を別にしたかったからです。
あと、エクスプローラーのフォントサイズが大きすぎたので
"window.zoomLevel": -0.7,
で、全体のズームレベルを下げて、エディタ部分は editor.fontSize で個別に設定しています。
他にも色々設定していますが、Python のコーディングに関係しているのはこんなところです。
こんな感じの見た目になっています。

Python 実行環境
Python は Python そのものやライブラリのバージョン依存が厳しい (バージョンを適切に管理する必要がある) ので Anaconda 等でバージョン管理を行うと聞いていたので、なんとなく「面倒だなー」と思っていました。
Mac の環境に色々な Python のバージョンやライブラリを入れたくなかったのと、間違えたときに元に戻したり、クリーンにしたりするのが面倒なんじゃないかとも思っていました。
VM Ware や ViurtualBox 等の仮想環境も考えましたが、なんとなく大げさすぎる気もしていました。
このように色々と考えているうちに以前「Software Design」という雑誌で Docker の記事を読んで、とりあえずコンテナを動かしてみたことを思い出し、これが使えるんじゃないかと思い (この段階では Docker コンテナの中で Visual Studio Code 動かせないかなーと思ってました) 色々と調べたところ Visual Studio Code から Docker コンテナに接続して開発ができることがわかりました。
Visual Studio Code で Docker コンテナを利用する方法については Google で「vs code docker コンテナ」等のキーワードで検索するとさまざまなサイトがヒットするので、そのようなサイトを参照しながら設定しました。
ポイントは
- Dockerfile をマニュアルで作成
- 複数のコンテナを使いたいので、docker compose を使う
ところです
私が現時点で行き着いている手順です
- プロジェクトフォルダ直下に .devcontainer フォルダを作成
特定のコンテナ用のフォルダ (Dockerfile などを格納) を作成
.devcontainer/python.devcontainer/python/Dockerfile を作成
いらんもんも入っていますが、だいたいこんな感じですFROM python:3.8 USER root RUN apt-get update RUN apt-get -y install locales && \ localedef -f UTF-8 -i ja_JP ja_JP.UTF-8 ENV LANG ja_JP.UTF-8 ENV LANGUAGE ja_JP:ja ENV LC_ALL ja_JP.UTF-8 ENV TZ JST-9 ENV TERM xterm ADD . /code WORKDIR /code RUN apt-get install -y vim less x11-xserver-utils python3-tk graphviz RUN pip install --upgrade pip RUN pip install --upgrade setuptools RUN pip install -r requirements.txtDockerfile からは requirement.txt に記載されているパッケージをインストールするようになっているので .devcontainer/python/requirement.txt を作成。今はこんな感じ
autopep8 flake8 psycopg2 requests.devcontainer/docker-compose.yml を作成
version: '3' services: python38: restart: always build: python container_name: 'python38' working_dir: '/workspace' tty: true volumes: - ..:/workspace:cached.devcontainer/devcontainer.json を作成
{ "name": "Tools by Python", "dockerComposeFile": "docker-compose.yml", "service": "python38", "workspaceFolder": "/workspace", "extensions": [ "MS-CEINTL.vscode-language-pack-ja", "ms-python.python", "ms-toolsai.jupyter" ], "settings": { "python.formatting.autopep8Args": [ "--max-line-length", "128" ], "python.linting.pylintEnabled": false, "python.linting.flake8Enabled": true, "python.linting.flake8Args": [ "--max-line-length=128" ], "python.autoComplete.extraPaths": [ "/usr/local/lib/python3.8/site-packages/" ], }, "postCreateCommand": "", }特別な設定は行っていませんが、autopep8, flake8 を pip でインストールしているのでその設定を行なっています。ちょっと行儀の悪い設定です。
これで、Viaual Studio Code でプロジェクトフォルダを開くと Docker コンテナが開始して Python が実行できるようになりました。
自分自身のこと
ブログのタイトルに「ほぼ老人」とか「定年が近い」とか書いていますが、実際には今度の 3 月で 60 歳になり定年退職する会社員です。なので、「ほぼ」とか「近い」とかは削って「老人のプログラミング日記」でもよかったのですが、「老人」という言葉に抵抗があって「ほぼ老人」にしました。「定年が近い」部分は実際に定年退職したら書き換えようと思ってます。
一旦は定年退職するのですが、65 歳までは定年後再雇用の嘱託社員として仕事は続けるつもりです。
職種はプログラマーです。自分の実力を計ったことはありませんが、そんなに優秀じゃないと思います。現在、主に使用している言語は C# です。数年前までは Java (バージョンは 8) を主に使っていたのですが、客先が変わって C# になりました。
C# は 12, 3 年前に「C#エッセンシャルズ」という本を買って読んだ程度ですが、.NET Framework はバージョン 2.0 の頃に VB.NET で自社内のシステムを開発したので、まったくなじみがないわけではありませんでした。とはいえ、10 年以上も前のことなので不安はありましたが「まぁ、なんとかなるだろー」という感じで着任して、結果として何とかなってます。とりあえず本は「Effective C# 6.0/7.0」と「More Effective C# 6.0/7.0」を読みました。
使用言語が C# にかわって、特別な感想はないのですが、C# の方が LINQ とかあってらくちんなきがします。決して私が Java の機能を使いこなしていたわけではないので、個人的な感覚です。
職業はプログラマーなので、日常的にプログラミングは行っているのですが、仕事以外でプログラミングすることは就職以来、約 38 年の間ありませんでした。それが、2~3 カ月前から突然、趣味でもプログラミングを行うようになりました。きっかけを箇条書きにすると
- 個人的に Knowledge - Free knowledge base system という情報共有サービスを使っていた
- 目的はなかったが VPS を借りた (WebARENA)
- 知人に OSS開発wikiツールのGROWI という情報共有ツールを教えてもらったので VPS に導入してみた
- Knowledge はやめて GROWI に移行することにした
- Knowledge の記事 (240 件程度) を GROWI に移行するのにツールを作る必要に迫られた。最初は Knowledge の記事をエクスポート / 加工して GROWI にインポートできるんじゃないかと考えたが Knowledge がエクスポートでコケるのでこの方法はあきらめた。240 件程度なのでマニュアルで移行することも考えたが、職業プログラマーとして「それはないんじゃないか」と思いツールを作ることにした
- Python が流行ってるらしいので、Python でツールを作ったが、仕事とは異なる面白さがあり、今後も「趣味」としてプログラミングを行っていこうと考えた
プログラミングをしていると、色々と調べたり、勉強したりすることがありますが、たいていは「コーディングして終わり」というのが多いと思います。仕事なら成果として残りますが、趣味だと使い捨てだったり、ちょっと調べてみただけで記録が残らないと思いましたので、老後の趣味の一環としてプログラミング関係のブログも始めることにしました。
家庭や仕事もあるので 1 日にプログラミングできるのは 1~2 時間程度で、毎日できるわけでもないので、このブログも頻繁に更新はできないと思いますが、ボチボチでも続けていけたらと思っています。